Conceptual Architecture of Customer Data Platform (CDP)

A customer data platform (CDP) is vital for businesses today. It brings together many dimensions of customer information so that a 360-degree understanding of a customer can be created and enriched with information from multiple sources. The final aim is to generate insights and AI models that can be used to drive better customer experiences, commerce (purchases, cross-sell) and operational efficiencies. However, enterprises often face the following two challenges: CDP programs often tend to become too complex leading to delays in returning value to the business. The systematically deployment of AI insights into operations as part of closed loop analytics remains a challenge for the industry. These challenges are a motivation for this post. The identification and implementation of a CDP does not have to be complex. In this post I wanted to present a bird’s eye view of some of the primary data and technical architectural components that business & technology leaders must think of as they embark on CDP programs – whether licensing a platform from a leading vendor or customizing an open-source product. Conceptual Architecture of Customer Data Platform – Explained Below A CDP can be thought of in terms of the following key functional blocks that span the overall data management lifecycle. It is helpful to think in terms of a functional architecture because it aligns the CDP more closely to its purpose. Let’s go bottoms up and build it up to enable an easier understanding of the multiple layers of Customer Data Platform Architecture. Level 0: The core data repository This is the core Customer 360 vision for a CDP. Ideally the development of this level should be aligned with the benefits that we wish to drive through AI and better insights aka personalization, audience analysis, cross-sell, better conversions, lower stock outs, decrease locked inventory, etc. This layer is often virtualized and consists of many functional blocks representing key data workstreams that will help us deliver the business objectives. For example, online clickstream data, transactions, purchase behavior etc. are often all part of this layer. To enable this comprehensive repository, the integration architecture must support both real time as well as batch ingestion mechanisms. At this level we also have the challenges of customer identity resolution and master data management. As with any data management program, creation of this stage means external and internal source management, multiple levels of staging and cleaning layers, data quality, data masking, and so on. Because of the inherent complexity of data management, this level can often overwhelm and dominate the scope of a CDP program. We must strategically define the (never ending) scope of Level 0 so that the business ROI can be generated in a timely manner. In other words, this layer must be incremental business value led. Level 1: Insights Generation Engine This architectural component is generally not considered as part of the core data repository but is critical to a CDP delivering the promised outcomes. Typically, the analytical use cases here are defined with a view to the desired business outcomes. For example, one of the most common insights to be generated is about customer segmentation. Any subsequent models must keep the segmentation in mind. The failure to keep segmentation front and center leads to sub-optimal outcomes. For example, we could be running a campaign based on incorrect segmentation thus leading to product cannibalization in the market, or we could be trying to fix an operational supply issue without clear insights on whether the issues disproportionately affect any specific customer segment. This level is also closely aligned with traditional business intelligence – the visualization of data according to the many slices and dimensions possible. Level 2: Program and Campaign Management This functional component of the CDP provides a structure to the campaigns and ensures that we do not create conflicts or overlaps between campaigns. This conceptual block is where most of the business facing programs are managed and executed. For example, we could be executing a cross-sell campaign and a product adoption campaign simultaneously, or premium brands could be running campaigns to the audience of a lower priced brand. So, this component, although not purely a technical one, serves as a key governance tool. This level also flows directly into the management reporting on campaign performance and attribution. We also often define the Level 0 or Customer 360 requirements at this level. That allows for the Level 0 layer to be built in an incremental and Agile fashion, with a view towards the business value expected. Level 3: AI Operationalization This functional block is the mechanics by which generated insights from Level 1 are integrated with either operational systems or customer engagement systems. Failure to consider this component of the CDP holistically is one of the primary reasons that AI programs often fail to be systematically utilized in production operations systems.; For example, as the insights on cross-sell targeting are generated and a campaign is kicked off, the extent to which this is automated and integrated with the eCommerce systems defines the success or failure of most CDP and AI programs. After all, this is the moment of truth. Insights implementation will depend on a variety of factors such as available budgets, technology constraints, or operational conflicts. However, partial versus full implementation must be analyzed and planned consciously. Technologically insights generated from AI are consumed and utilized via various means such as an API gateway. This level also serves to build in the reverse data feedback loops to feed into level 0. When this cycle is optimized, then the closed loop analytics mission is properly met. Level 4: Management Reporting The final component in the conceptual architecture of customer data platform (CDP) is the generation of insights for decision making and control. This is where we generate metrics on sales performance, product adoption, etc. This level also has the traditional components of exploratory data analysis and hypothesis so that new ideas can be generated. We cannot control and improve what we cannot measure. So, thinking of
Utilizing SASE for Improved Cybersecurity in Enterprise Applications

What is SASE in Cybersecurity? Secure Access Service Edge (SASE) is the next step in cybersecurity. It is a rapidly emerging practice that seeks to unify disparate security practices into a cohesive cloud delivered model. What do we mean by that? Today, most enterprises have a variety of deployment models for their applications, data and end user devices. To address this topology, a variety of security practices have been followed starting from securing local networks in the physical building, addressing mobile devices, and securing multiple business applications in the cloud. SASE seeks to simplify this model by delivering verification with a Security-as-a-Service model on the cloud. Moreover, the SASE framework does not assume a centralized service. Instead, it is assumed that the security should be verified at the edge – closer to where the users are. That gives rise to higher performance while raising the security levels. Gartner predicts that by 2024 almost 40% of all enterprises will have a concrete plan to move to the SASE model. So SASE is here to stay. Key Components of SASE framework in Cybersecurirty The following are some key components of the SASE framework. As you can see, they are already been done to varying extents. So, SASE is really just a more conscious evolution of cybersecurity practices: Zero Trust As we move to the cloud, it is apparent that traditional definitions of trust will also change, perhaps for the better. In the Zero Trust model, there is a continuous verification, aka authentication and authorization. Contrast that with traditional approaches that used a “trust but verify” model. For example, if you are inside a physically secured building, you are assumed to have clearance. In the Zero Trust model, that vulnerability is addressed through verification barriers based in roles, usage, and other parameters. This continuous verification in the zero trust model is done through a variety of techniques including monitoring of logs and usage patterns. As a result, the impact radius of a breach is presumably going to be reduced as access will be restricted as close to a security event as possible. A zero trust based model will also reduce human errors and latencies in case authorization and authentication parameters change for applications, individuals, and their devices. Firewall as a Service (FWaaS): As applications have moved to the cloud, traditional firewalls have evolved into being offered on the cloud. However, as complexity of the applications, use of third-party SaaS services, and user access patterns changed due to remote and mobile access, firewalls had to emerge too. The firewall as a service model simply means that all traffic needs to be routed through a cloud-based firewall which can make the right decisions depending on the context of the use and the latest policies. Just as in the zero-trust model, this has significant advantages over the traditional fragmented means of protecting access. Software Defined Wide Area network (SD WAN): SD-WAN allows organizations to manage the network from a central location instead of relying on traditional wide area network (WAN) technologies like MPLS. The deployment is simplified because SD-WAN allows administrators to set policies and manage the network from a central location. The use of software to manage and control the network also eliminates the need for proprietary hardware, reducing cost and complexity. SD-WAN is an essential part of the SASE framework. Central Control Tower The central control tower is necessary for centralized management and a single point of control over network and security functions. It is responsible for enforcing security policies, providing visibility into network traffic (for monitoring), and automating network deployment (such as SD-WAN) and other security functions. Using a control tower simplifies overall security operations and reduces the time taken for decision making by making sure that the necessary data is available centrally and in real time. Next Steps The move to SASE (Secure access service edge) is the next logical thing in streamlining and evolving your cybersecurity maturity. It is a crucial capability to protect your business from both bad actors and operational oversight. Get in touch today for an audit of your applications and cybersecurity landscape. We’ll help you develop a practical roadmap towards SASE adoption and recommend the software platforms to adopt.
Integrating Data for Your Customer Data Platform with Domo

In my last post I outlined a 5-layer conceptual architecture for your Customer Data Platform (CDP). I reiterated that a CDP program should be viewed as a way to achieve closed-loop analytics for your enterprise, not just a centralized data store. In this blog, I’ll outline the core foundation of all Customer Data Platforms – a unified data repository enabled by a dynamic enterprise data integration framework. I’ll highlight a few salient items to keep in mind to ensure the resiliency of your technology and data architecture. I’ll use the Domo integration cloud to illustrate the principles of not only populating the target repository but also updating the original sources with enhanced information coming back from the repository. As a partner of Domo, Ignitho is partnering with clients on their digital transformation journeys. We also partner with Micrsosoft and AWS for Domo implementations. While there are overlapping and overlapping technology offerings from each, this blog focuses on Domo and brings out our philosophy on how to ultimately enable closed loop analytics for your enterprise. The Core Foundations When we think of a CDP, we immediately think of the various data integrations we will have to build in order to get the data from various source systems into the central data repository we call our CDP. As part of that journey, we must tackle data reconciliations, data quality because of inconsistencies, differences in real-time versus batch feed, and so on. Since most of us have undertaken this challenge so many times, a robust methodology has been built up around it. Domo too offers a comprehensive collection of quality integrations and provides several advantages as well. ETL, for instance, is easier with Domo’s magic ETL. The drag-and-drop capability needs no technical skills thus effectively enabling business-led teams. The SQL Based ETL is also provided to go the extra mile where intricacies are to be explored and handled. There are often linkages between different datasets. Domo’s data lineage analysis capabilities allow users to see the cascading impacts of changes in a dataset. Domo also allows data governance to be taken off the technical task list with capabilities to Capture and audit all auditable formats Build, schedule and automate jobs to eliminate downtime Scale infra on demand, up and down Certify the content of datasets through customizable workflows Finally, federated data connectors allow us to access data directly where it is stored instead of needing to build or use additional cloud connections. Building on the Foundation – The Enterprise Integration Framework The CDP is not just a destination of the data to enable analytics. It also starts serving as a single source of truth for the enterprise. In addition, it is the perfect place where we can do enrichment of data and feed it to the other systems that need the enriched information. One of the key capabilities that an organization needs to create an enterprise data fabric where applications can plug in to not only feed data in, but also to pull out (or receive by push) relevant information. This is provided by the Domo Integration Cloud. For instance, a common challenge is to combine data sources and extract analytics out of it. Domo’s pipelines make it a breeze to perform this activity, without the need to write a single line of code. The core aspects of data quality – accuracy, consistency, compliance, and relevance – are enforced in the integration process to ensure quality gates are in place. Once they are set up, the quality of insights generated from the CDP is high. Thus, insights are more reliable, create a higher ROI on business investments, and deliver the intended benefits in an accelerated period. There is also a reduced need to perform manual data governance activities thus reducing costs overall Summary I hope this blog was useful in understanding the data integration layer of the CDP. The Domo integration cloud makes it easy to not only create your CDP, but also to create a responsive, enterprise integration layer. In my next blog, I will highlight how we should be thinking about enabling business intelligence reporting and visualization of the data in the CDP. If you would like to discuss your CDP roadmap and technology fitment, please get in touch.
AI Led Customer Data Platform (CDP) for Retail

A Customer Data Platform (CDP) for retail helps retailers build a 360 degree view of their customers. This is important to improve customer experience and enhance commerce activity. In this blog, I wanted to highlight the difference between a CDP and a data lake, and then outline some key use cases in retail that you should pursue a CDP for. CDP vs Data Lake – The Difference Since they both are meant to ingest and store large amounts of data, are data lakes and CDPs the same? It turns out that the key difference is in the intent of the storage. A data lake is meant to be a store of unprocessed data on which desired business intelligence will be built as needed. Typically, we have seen data streams from all parts of the enterprise sent directly to the data lake. The idea has been that we should capture everything that we can because we never know what special insights a piece of data can hold. Once we have all the data coming in, then we can sift through it and extract the insights that we need. A CDP on the other hand is created with a deliberate purpose. The data is ingested after we have defined what we need based on the kind of analytics we want to build to serve a specific purpose. Since we are no longer looking for a needle in a haystack, arguably the time to create a CDP is much shorter. On the other hand, by being laser focused and building incrementally, there is always the possibility that we are leaving something of value out during the data integrations. For this reason, generally, data lakes will also co-exist in an enterprise. Indeed, the purpose of a CDP is often the same business intelligence scenarios and AI use cases that a data lake would enable. But given the way it’s conceptualized a CDP provides quicker ROI. You could also think of a data lake powering a CDP as one of the many architectural approaches we may follow. In both cases, Domo provides ready connectors to a variety of systems including online commerce, clickstream data, and transactional information from systems such as fulfilment systems and the ERP. These connectors allow us to expedite the time to market significantly. They also assist in performing systematic identity resolution so we can build holistic customer profiles. What does a Retail CDP look like? Our approach is to initiate a CDP program by clearly defining the purpose of the CDP. Then we select the right cloud platform, the right sources, the right Domo connectors, outline the Domo BI engine, and deploy the right AI modeling. This helps us make sure that we deliver ROI as soon as possible to the business while keeping the path open for incremental value development. The 5 layered customer data platform architecture program outlines our thinking on this. For example, as we started to define our own Retail CDP solution as a Domo App, we started by speaking with clients about the top use cases they were looking for. The following 3 use cases surfaced as high priority. There is a Retail App that is provided by Domo already on their marketplace. It does a great job of demonstrating how dashboards can be deployed quickly to start yielding ROI. In this blog we’ll extend that concept to include AI and other uses as well. Marketing Use Case for a CDP With so much going on in the marketing technology with content management, dynamic pricing, churn prediction, and advertising on multiple channels, it has become imperative for brand managers and marketers to maximize the value of their martech investments. A CDP is the perfect complement to the martech stack because it can not only provide aggregated information of a customer or a segment, but it can also quickly deliver predictive, and often prescriptive insights through AI to positively assist the customers in their journeys. Intent-based targeting and analytics is a great use case to get the customers to ultimately complete their purchase. Using drop off and journey data available to us, combined with customer demographic data, we can not only encourage customers to take action, but more importantly we can improve customer journeys and address objections better. For example, we helped a client pinpoint channel conflicts between multiple brands by effectively using multiple sources of data. By anonymizing and bringing the promotions data of multiple brands in one place, we were able to ensure that the customer segments were updated to reflect the brand positioning of the various products – premium vs value was the easiest one. In the absence of this analytics, the brands were not only realizing lower ROI on their spend, but they were also causing brand confusion in the minds of consumers. Another great use case is of omni-channel commerce: when customers drop off online, we could continue the journey in the store and vice versa. Even when online, retargeting is a great way to keep customers engaged. A complementary technique is to use intent data and segmentation to predict recommendations on what customers might want next. Today’s recommendation engines are getting better but there is still a lot that can be improved. Domo provides connectors to a variety of marketing systems which accelerate the time needed to deploy effective analytics capabilities. Store Analytics & Pricing Use Case In any retail business which has multiple locations, it is important to keep track of store performance and the factors that drive it. It is also critical to understand how the pricing changes and promotions can influence commerce activity. The readymade Domo retail app does a great job of providing you with dashboards around these important metrics. It has a ready dashboard that is powered by a well-defined schema. All we have to do is to ingest the data. Ignitho’s solution builds on top of this solution by providing AI powered insights. This enables you to take prescriptive actions. For example, one of the AI models is for customer
Improving Data Governance with MS Purview to Deliver Better AI

Every large enterprise faces tremendous challenges with management of data, maintaining compliance, and identifying the sources of truth for better business performance. Often, it is not feasible to store and manage everything centrally as the application portfolio evolves constantly and business moves at different speeds across the enterprise. Entropy is real and a very good thing to have. So, in this blog I wanted to introduce a solution from Microsoft to address this need. Microsoft Purview is a comprehensive solution to help us deliver a bird’s eye view of data across the enterprise. Create unified data maps across a diverse portfolio Microsoft Purview allows us to create integrations with on-premises, cloud, and different SaaS (Software as a Service) applications in your portfolio. All we need to do is to set up the right integrations with the right authentication & authorization. Purview does the rest. The data can then be classified using custom or predefined classifiers. This is an especially useful exercise to understand how data is fragmented and stored across multiple systems. As we map out sensitive data elements, it then becomes easier to identify sensitive data. This identification has many real-world use cases including: Compliance with data privacy and masking rules Regulations around data domicile Compliance with GDPR (General Data Protection Regulation) In almost any enterprise technology transformation program, the importance of identifying the golden source of data becomes critical. Often, these data mappings are kept in offline documents and sometimes even as latent knowledge in our minds. However, as the application portfolio evolves, this becomes incredibly difficult to manage. A solution such as Microsoft Purview provides immense benefits in providing a simpler way to manage data lineage and discoverability. The ability to use business friendly names allows even business users to search and determine where data elements are located and how they are flowing. In addition, technology impact analysis becomes much easier when we know how a change can affect the data map. Microsoft Purview also has a feature for data sharing. If that is feasible with your implementation, then that is an excellent mechanism to share data between organizations and maintain the data lineage visibility. AI & Analytics Improvements It is well known that almost 50-70% of the effort in a typical AI program is spent on aggregating, reconciling, and cleaning up data. Adopting Microsoft Purview helps reduce the source of these complex and time-consuming issues to a greater extent. Data pipelines are easier to examine, refine and build if we can be sure of the data lineage, systems of record, and the sensitivity of data. And the resulting aggregation is more usable with higher data quality. We can also better avoid inadvertent compliance breaches as we ingest the data for our analytical models. As the need for AI increases, and as teams of data scientists change frequently, a systematic solution becomes important. The sharing feature of Microsoft Purview can also be used to aggregate data that can be used for analytics. Potentially this can transform the way we have traditionally thought about data aggregation and integration into destination data stores. Next steps I hope I was able to bring out the benefits of using Microsoft Purview clearly. Visibility into data across your digital real estate Mitigates compliance risks Accelerates the ROI (return on investment from AI and analytics programs That said, it is a subscription service from Microsoft so the right business case and use cases should be built before adoption. In addition, like with any new initiative, there are many topics such as security, collections hierarchy, authorization, automation etc. that merit a deep dive before adoption. If you want to explore data governance and Microsoft Purview further, please get in touch for a discovery session.
How to Implement an Enterprise Data Framework

In this blog I’ll describe a solution to an urgent priority affecting enterprises today. That question is “How to implement a closed loop analytics framework that can be scaled as the number of use cases and data sources increase?”. This is not an easy problem to solve because by its very nature, any technology implementation gets outdated very quickly. However, thinking in terms of the entire value chain of data will help channel this inevitable entropy so we can maximize the value of our data. The 5 Stages of a Closed Loop Data Pipeline Typically, when we think of developing a new application or digital capability, the focus is on doing it well. That implies we lay a lot of emphasis on agile methodology, our lifecycle processes, devops and other considerations. Rarely do we think about these two questions: What will happen to the zero and first party data that we are about to generate as part of the application? And (to a lesser degree) what existing insights can the new application use to improve the outcomes? As a result, the integration of data into the analytics AI pipeline is often accomplished as part of separate data initiatives. This according to me is a combination of data strategy and data operations stages of the closed loop analytics model. Stage 1 From a data strategy perspective (the first stage), understanding the value of zero-party and first-party data across all parts of the enterprise, and then creating a plan to combine relevant third-party data is critical. It defines how we adopt the capabilities of the cloud and which technologies will likely be used. It also helps us create a roadmap of business insights that will be generated based on feasibility, costs, and of course benefits. Finally, feeding this data strategy consideration into the governance of software development lifecycle helps unlock the benefits that enterprise data can deliver for us. Stage 2 The second stage which is closely linked is data operations. This is the better-known aspect of data management lifecycle and has been a focus of improvement for several decades. Legacy landscapes would use what are called ETLs (batch programs that map and transfer data) into different kinds of data warehouses after the data has been matched and cleaned to make sense. Then we implement various kinds of business intelligence and advanced analytics on top of this golden source of data. As technology has progressed we have made great strides in applying machine learning to solve the problems of data inconsistencies – especially with third party data received into the enterprise. And now we are moving to the concept of a data fabric where applications are plugged straight into an enterprise wide layer so that latencies and costs are reduced. The management of master data is also seeing centralization so that inconsistencies are minimized. Stage 3 Stage 3 of the data management lifecycle is compliance and security. This entails a few different things such as but not limited to: Maintaining the lineage of each data element group as it makes it way to different applications Ensuring that the right data elements are accessible to applications on an auditable basis Ensuring that the data is masked correctly before being transmitted for business intelligence. Ensuring that compliance to regulations such as GDPR and COPPA is managed Encryption of data at rest and in transit Access control and tracking for operational support purposes As is obvious, the complexity of compliance and security needs is not a trivial matter. So I find that even as the need for AI and Customer Data Platforms (CDPs) has increased, this area still has a lot of room to mature. Stage 4 Stage 4 is about insights generation. Of late this stage has received a lot of investment and has matured quite a bit. There is an abundance of expertise (including at Ignitho) that can create and test advanced analytics models on the data to produce exceptional insights. In addition to advanced analytics and machine learning, the area of data visualization and reporting has also matured significantly. From our partnership with AWS, Microsoft and a host of other visualization providers such as Tableau, we are developing intuitive and real time dashboards for our clients. However, I believe that the success at this stage has a lot of dependency on the first 2 stages of data strategy and data operations. Stage 5 Stage 5 is another area that is developing in maturity but is not quite there. This stage is all about taking the insights we generate in stage 4 and use them to directly improve operations in an automated fashion. From my experience I often see 2 challenges in this area: The blueprint for insights operationalization is still maturing. A logical path for a cloud native organization would be feed these insights as they are generated into the applications so that they can result in assisted as well as unassisted improvements. However, because of the lack of these automated integrations, the manual use of insights is more prevalent. Anything else requires large investments in multi-year tech roadmaps. The second challenge is due to the inherent entropy of an organization. New applications, customer interactions, and support capabilities must constantly be developed to meet various business goals. And as data strategy (stage 1) is not a key consideration (or even a feasible one during implementation), the entropy is left to the addressed later. Summary The emergence of AI and analytics is a welcome and challenging trend. It promises dramatic benefits but also requires us to question existing beliefs and ways of doing things. In addition, it’s also just a matter of evolving our understanding of this complex space. In my view, stage 1 (data strategy), stage 3 (compliance and security) are key to making the other 3 stages successful. This is because stage 2 and stage 4 will see investments whether we do stage 1 and 3 or not. The more we think about stage 1 and 3, the more will our business benefits be amplified. Take our online assessment on analytics maturity and
Building the Cognitive Enterprise with AI

Enterprise Cognitive Computing (ECC) is about using AI to enhance operations through better decision making and interaction. In fact, this is how the impact of AI is maximized by directly influencing operational efficiency and customer experience. Implementations of enterprise cognitive computing are a natural combination of digital, data, and enterprise integration. That’s simply because the insights we generate must reach the target application points, and then they must be used by digital means. In this blog we will outline a few real-life use cases and then discuss the key enablers of Enterprise Cognitive Computing. Use Cases Customer Experience One of the key focus areas for Ignitho is helping media publishers engage customers better. As business pressures mount, the need to generate new revenue models and provide customers with highly personalized experiences is becoming vital. Given the large trove of zero and first party data, enterprise cognitive computing can generate the contextual information needed to provide unique experiences to customers. In addition, while the traditional analytics use cases have been to show customers what they have seen before and liked, perhaps differentiation can be created by capturing appropriate zero party data to do something different and hyper personalized to an audience of one. These stated customer requests captured as zero-party data can then be channeled into the algorithms to present a better overall experience, all the while monitoring customer receptiveness and continuously refining their journeys by improving our interactive digital capabilities. Operational Improvements Improvements in natural language processing (NLP) have opened the door to substantial efficiency improvements. For example, incoming customer remarks and comments are often parsed manually to a high degree. Now, better AI capabilities (NLP) and integration with enterprise systems to build full context will allow increased levels of automation. Not only does this reduce costs, but it also increases customer experience significantly. Similarly, improvement in automated fraud detection and suggestions of next best actions are resulting in customer service teams becoming much for efficient and empowered. As a result of enterprise cognitive computing, our customer interaction channels can be more responsive. They can also be made more interactive through the use of conversations agents such as chatbots. Key Enablers of Enterprise Cognitive Computing While being AI led is the core of Enterprise Cognitive Computing, it is really a strategic combination of AI, data management, enterprise integration & automation and digital engineering. Artificial Intelligence (AI) : Advances and implementation of AI techniques is no doubt the tip of the iceberg and critical to the success of enterprise cognitive computing capability. With advances in natural language processing (NLP) and machine learning, the data and context of operations can be much better understood and acted upon. We have an abundance of talent that is leading to creation of advanced analytical models for various uses, testing them, and generating insights for almost every area of business across the customer lifecycle – attracting, acquiring, servicing, and retaining. Data management: This can be considered to be the backbone of enterprise cognitive computing. Successful implementation of AI needs high-quality, diverse, and consistent data. Modern data management techniques such as building a Customer Data Platform (CDP) to creating enterprise-wide data pipelines are helping organizations to cope with the enormous amounts of data being generated. Ignitho has a comprehensive 5 step data management framework to address this issue. Digital Engineering: You can consider digital engineering to be the channels through which insights are propagated to the systems of engagement. These could be conversational agents on the website or plugin within portals that allow customer service or operations to work better and faster. As digital tools and technologies become more widely available, selecting those that meet the needs of your enterprise in the best way possible is crucial. Through its product engineering offering aided by its innovation labs. Ignitho can rapidly enable experimentation with emerging tech along with microservices and API-based architectures to promote agility and composability. Integration & Automation: Consider this as the plumbing of your enterprise. To create robust data pipelines or a data fabric, it should be possible to create an enabling architecture. Enterprise integration enables that to happen. These integration techniques allow for applications to communicate with each other without having to build non-scalable, point to point integrations. In addition, automation techniques such as Robotic Process Automation can bridge the time to market gap for new capabilities. That’s because while technological remediation of gaps in the business process (e.g. sending data automatically to another application) can be delayed because of costs and other factors, the intended results can still be achieved through a judicious use of RPA (robotic process automation). An Exciting Future Enterprise Cognitive Computing promises highly contextual experiences at scale. In order to tap into the full potential of this innovation, we must think strategically in terms of the entire gamut of data and technology enablers needed. In our Data Analytics Assessment here, we cover the end-to-end life cycle, so feel free to check it out and see where you stand.
The 5 Principles that Guide Frugal Innovators
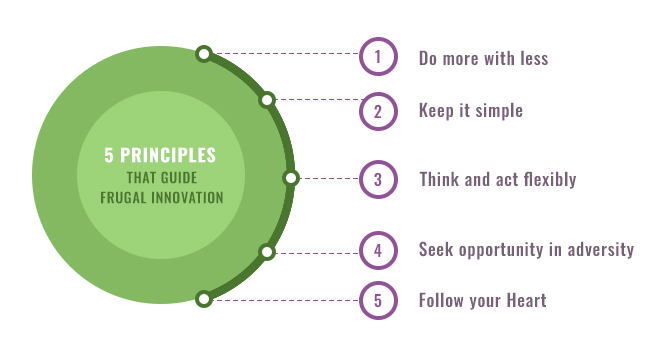
In this second blog in a 3-part blog series on Frugal Innovation the focus is on the principles that guide frugal innovators across the globe. Think of innovation and invariably Apple comes to mind. Its products are the embodiment of Silicon Valley innovation. Innovation at companies like Apple typically involves technology (often for the sake of technology), huge budgets and structured, secretive processes. While this is a powerful way to create new solutions, innovation doesn’t have to be based on unlimited purse strings and blue-sky thinking. Powerful solutions can also come from resource constraints and from the challenges that consumers and enterprises face. As I discussed in my previous blog, frugal innovation is an approach that thrives on resource constraints and creates relevant solutions for challenges that plague consumers and enterprises today. Together, Ignitho and I have created a methodology we call Frugal Technology Innovation for Enterprises to help companies innovate faster, better and cheaper. In this blog I will share the 5 principles that guide the frugal innovator: Do more with less Good design thinking and saying “no” is the key to coming up with an effective solution with fewer resources in less time. Such “lean” thinking is increasingly relevant to firms of all sizes and sectors. Typically, CIOs face financial or resource constraints whenever they try to come up with innovative ideas or support a disruptive technology. Often, these constraints force them to give up on the innovation and continue with business as usual. A frugal innovator, on the other hand, tries to meaningfully use the minimal resources at his or her disposal and deliver innovation. A frugal innovator is always associated with a desire to do more with less, not focusing on problems but instead giving importance to opportunity in delivering an innovative technology solution. Keep it simple Innovators often focus on coming up with a perfect solution. But this often leads to unnecessary complexity. And cluttering a solution with inessential features adds to the cost without delivering significant additional value to the user. A common misconception in innovation is that it can happen only at an organisational level if it is big, hairy and ambitious. In today’s business context, however, where enterprises are struggling to conduct business as usual, an innovative solution which demands an investment of millions, is sure to be shot down without a second thought. Frugal innovators, therefore, focus on delivering quick and effective results. Their modus operandi is to identify a small element of a wider business or IT problem as a starting point or focus on a stakeholder who is willing to take the plunge to do something different or innovative. Applying the methodology of Frugal Technology Innovation for Enterprises, a frugal innovator works to deliver tangible results. Think and act flexibly Businesses operate in fast-evolving environments. Mergers and acquisitions are more common than ever before. A disruptive technology might come in at any point and shake up the established order. Witness how the private cab industry was disrupted by the arrival of Uber. There is a need to react quickly in an ever-changing environment. Innovation is about finding and acting within windows of opportunity. Frugal innovation helps to do this by delivering quick results and enabling quick adaptation to the change. Understanding your target market should be the key step in your journey of Frugal Innovation. Customising a product according to the environment of your target market should be the main priority of a Frugal Innovator. Frugal innovators need to be flexible to changing situations and the challenges that come up from time to time. Frugal innovators react quickly and flexibly to windows of opportunity, react quickly to disruption and react quickly to external changes to deliver tangible innovative solutions through technology. Seek opportunity in adversity Business is not static, and adversity is a reality. Frugal innovators do not worry about change; instead, they consider every change as a positive driver of innovation. Frugal innovators seek to convert adversity into opportunity. A prime example of identifying an opportunity in the face of adversity is that of Airbnb, where its founders were not deterred by the presence of giants in the hotel industry with millions of hotel rooms among their assets. The only way to disrupt this and enter a crowded market with limited resources at their disposal was to define a completely new business model, using ordinary homes as the “real estate”. Follow your heart Innovators face constant criticism from various quarters. They can be seen as an expensive distraction or as a blue-sky indulgence, especially in touch economic times. The frugal innovation approach offers a more acceptable alternative for innovators to follow their hearts and achieve their targets with conviction. It gives them the conviction to be disruptive, to be first movers, to stand up to people who oppose them, and to be different. Having the courage to do what your heart tells you to do, and indeed be a pioneer Frugal Innovator, is an essential trait for a successful frugal innovator. Starting small, learning quickly and scaling rapidly is key to delivering Frugal Technology Innovation for Enterprises. The principles above need to be adopted by the IT leaders of today to bring about a more sustainable revolution. To do so, IT leaders also need an IT partner to help them learn these principles by working alongside them to deliver frugal yet innovative technology solutions: a partner who will build quality solutions through Rapid Prototyping and will also help deliver Scalable Solutions. Ignitho is leading the market for UK enterprises in this area today. In my upcoming blogs, we look at how to approach Blue Sky Thinking in a Frugal Innovation Approach and some of the Success Stories in Frugal Innovation.
Using AWS Glue to Accelerate Your AI & Analytics Initiatives
As AI and analytics becomes table stakes for businesses, there is a need to manage and utilize many different sources of data. These data sources can be of many different kinds – structured, semi-structured and unstructured. As I outlined in my blog earlier this year, one of the top challenges faced by data scientists is getting timely, high-quality data at the right time so that they can allocate their time to analysis and insights, versus data management. AWS Glue comes as a savior. At its core, it is a fully managed cloud ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams. But I feel that it can be a powerful tool that can truly help accelerate your strategic data initiatives. In this blog we’ll look at when to use it, and what to think about before implementing it. What is AWS Glue Enterprises often sit on data mines, not fully extracting the monetary benefits of leveraging the insights for operational improvements, customer experience, and revenue growth. On average, almost 70% of a data scientist’s time is spent cleaning incoming data, aggregating the sources, and making them ready to be used for analysis. This is where AWS Glue comes in. It helps you monetize your data debt, and sets up the roadmap for higher overall organizational maturity. AWS Glue positions three core components at the highest level – a data catalog, ETL processing, and scheduling. By considering the architecture in this manner, we logically begin to focus on the outcomes rather than the procedural aspects of data management. We think this is a very nice soft benefit. The AWS Glue Data Catalog is used to track all data, data locations, indexes, run metrics, and schemas. It makes the data accessible, converting unstructured data into preferable schema-oriented table formats. It uses “crawlers” and “classifiers” to assist in the identification of data schema and its creation in the Data Catalog. AWS Glue crawlers can crawl both file-based (e.g., unstructured) and table-based (structured) data store via Java Database Connectivity (JDBC) or native interfaces. It can securely connect to multiple data sources and saves the time by doing away with the need of reconnecting every time. Then together, the three components significantly reduce manual effort by automating the entire data discovery and aggregation process. Consequently, we also reduce the probability of errors. The second major benefit is that AWS Glue is serverless. This means that there is no infrastructure to set up or manage. In turn this implies that the agility factor to go from data to insights is high. Illustrative Case Study On a recent project, the operations team was facing challenges in getting their key customer analytics reports out on time. There was a significant level of manual effort needed for data pipelining (integration) from multiple sources. The data had to undergo several levels of adjustment to be ready for analysis. Inconsistencies between data sources had to be resolved very frequently. This overhead was affecting reporting and business intelligence latencies negatively. As a result, the client team was encountering challenges in their ability to engage their customers in data-driven performance conversations to create the right strategies for the next customer marketing cycle. In order to meet this challenge of streamline business reporting and analytics process, we used Glue to act as a supporting tool to the regular process flow. Multiple files containing millions of records every cycle were processed. Some of the data was structured (e.g., customer data) while some was semi-structured (e.g., advertising information) and the rest of it was unstructured (e.g., user generated content). An important point to note is that we masked the data (using PySpark) that was processed by Glue to maintain compliance and reduce risk. Processing was in memory, data was access restricted, and only masked data was allowed as output. We customized the sorting and filtering in the business reports and other output in a way that no sensitive information was compromised. The data sources were segregated into specific folders. Then the AWS Glue crawlers helped us crawl the files and structure the data properly. Glue split the jobs and ran them in parallel so we could truly leverage the power of the cloud. With the latest Glue updates, we also now get much better UI and faster processing. Since AWS Glue is serverless, we were able to start quicky with a low cost, pay-as-you-go option. One of the key benefits was the trade-off between time and cost. We went from a largely manual process to an automated process which was a huge time saving. Finally, there are inherent benefits of a cloud-based data infrastructure over the traditional approach. We were able to store and process very high volume of data which otherwise would have required a significant scalability management overhead in terms of on-premise infrastructure. What to watch out for? One consideration is that as you adopt any cloud-based solution, costs can quickly rise. One of the ways we were able to contain that is by being conscious of what we needed. For example, for structured input we used limited AWS Glue features such as crawlers that look at the incoming file formats and validated them on an automated schedule. Since we had a lot of files, we also found it very useful to use crawlers to help redesign the files. We also ran a lot of processing outside the Glue environment using Python because the processing within a managed cloud service can quickly get expensive. Finally, like any technology tool, sound knowledge and real-life experience is required in order to maximize the benefits you can get from AWS Glue. Creating a robust data management strategy using a top-down approach using design thinking principles is very helpful. It allows you link the enterprise rollout of AWS Glue in a manner that is substantiated by associated business benefits at every stage. Next Steps We recommend that you give AWS Glue a try. It can help you get started quickly with your data management efforts and ROI can be realized within as little as 6-8 weeks. We can help you run a pilot, and conduct a discovery workshop to create a roadmap that matches your business goals. Take our data strategy assessment to see where you are on your data management maturity.
The Biggest Data Engineering Challenges of 2022
The dynamic data engineering technology space of today is propelled ahead by the decisive shift from on-premise databases and BI tools to modern and advanced cloud-based data platforms built on lakehouse architecture. Today’s challenging data environment stipulates, reliance on multiple technologies to keep up with scale, speed and use cases. The cloud data technology market is advancing swiftly, and includes an extensive set of open source and commercial data technologies, tools, and products, unlike the on-premise data warehouses of the past. Organisations are developing DataOps Frameworks and Functions to be maximize the value of their data and to be in relevance. To enable automated and continuous delivery of data to business intelligence analytics and data powered products, processes and DataOps tools are in place. As per a recent study by Gradient Flow and Immuta, respondents cited these areas as the most challenging in the data engineering space: Data Quality and Validation; Monitoring and Auditing for Compliance; Masking and Anonymization; and Data Discovery. We at Ignitho have been building capabilities, across our Data Engineering Practice to mitigate these challenges in the most holistic way possible. With potential sources of error increasing day by day; factors like volume, variety, velocity, data source type, and the number of data providers, are playing a huge role in how we face the concern of data quality. Solutions based on our Informatica and TensorFlow Data Validation capabilities have helped our clients tackle data quality issues and challenges impacting critical and products, depending on the accuracy of Data. At times, when organizations’ have to handle myriad of data sources and data types, such as unstructured data consisting of text, images, audio, and video; the data integration solutions with Apache Spark, dbt and Hive as well as managed services like AWS Glue, Dataform and Azure Data Factory has been adding value to our clientele’s data compliance efforts. Data Masking and Data Encryption are distinct data privacy solutions. Ignitho’s regulated approach on GDPR, HIPAA, CCPA, and SOC 2 has been pivotal in removing the misconception among data stewards on Data Governance and Data Privacy when considering data anonymization solutions, that encrypted data is indeed a form of data masking. A recent study indicated that close to 1 in every 4 organizations, do not have a structured Data Catalog or Discovery tool. As they grow, the amount of raw and derived data they generate and store rises, and users need tools to help them discover the right data resources. Ignitho’s expertise in the areas of Google Data Catalog, Collibra, and Azure Data Catalog, are assisting organizations drive adoptability. Headquartered in the US, Ignitho services its customers through its offices in London, UK, and New York and Richmond, USA, and its development centers in Brighton, UK and Kochi, India. We are rapidly gaining recognition as a market leader in Frugal Technology Innovation for Enterprises – the ability to do more with less.